
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- aws
- 테라폼함수
- pptxpdf
- terraform
- 가시다스터디
- 테라폼조건식
- terraform_data
- (user)없애기
- t101
- pptpdf로변환
- (user)terminal
- pythonpptpdf
- cidrhost로EC2의ENI에10개의ip를 장착
- macterminal(user)
- 테라폼스터디
- githubbasic
- mac user
- 깃허브기초
- terraformazure
- azureresource
- awsworkshop
- awsglue
- data개념
- azureterraform
- t103
- 테라폼상태
- Azure
- mac(user)
- pptpdf
- 테라폼조건문
- Today
- Total
fullmoon's bright IT blog
[AWS workshop] Ecommerce 유저들을 위한 추천 서비스 구현하기 :: DATA LAKE (1) 사전 준비, 데이터베이스 데이터 수집하기 본문
[AWS workshop] Ecommerce 유저들을 위한 추천 서비스 구현하기 :: DATA LAKE (1) 사전 준비, 데이터베이스 데이터 수집하기
휘영청 2021. 8. 25. 16:42※ 본 글은 Study 용으로 AWS workshop 실습 내용을 정리한 것입니다.
실습 개요 :: DataLake on AWS
실습 개요 Ecommerce 유저들을 위한 추천 서비스 구현하기 이번 워크샵에서는 가상의 시나리오를 통해 추천 서비스를 구현해봅니다. 추천 서비스를 구현하기 위해서는 발생하는 데이터를 수집하
public-aws-workshop.s3-website.us-east-1.amazonaws.com
[목차]
1. 사전 준비
2. 데이터베이스 데이터 수집하기
3. 웹 엑세스 로그 데이터 수집하기
4. 데이터 탐색 및 가공하기
5. 추천 캠페인 생성하기 (Optional)
6. 자원 삭제하기

Amazon S3 : 스토리지 서비스는 데이터 레이크 역할
Amazon Kinesis & AWS Glue : 데이터 레이크에 데이터를 모으기
Amazon Kinesis : 스트리밍 데이터를 관리
AWS Glue : 데이터를 준비하고 로드하도록 도와주는 완전 관리형 ETL(추출, 변환 및 로드) 제공
AWS Athena : 모은 데이터를 간편하게 분석
Amazon Personalize : 추천 서비스를 구성하고자 하는 경우 개별화된 서비스 추천
[Architectre]

1. [사전 준비]
- Region : 버지니아 북부 리전
- Keypair : EC2에서 생성
- Cloudformation 생성 : VPC 기본 환경, IAM User/Role, EC2(Webserver), RDS, Sagemaker Notebook
https://s3.us-east-1.amazonaws.com/public-aws-workshop/demogopersonalize/demogo-personalize-cloudformation-2021-0324.yaml
- Stack name : demogo-mongstore
- Availability Zone 1 : us-east-1a
- Availability Zone 2 : us-east-1b
- KeyName : 생성한 키
- SSHFrom : 0.0.0.0/0
Stacks 생성!
[Stack으로 만들어진 Architecture]

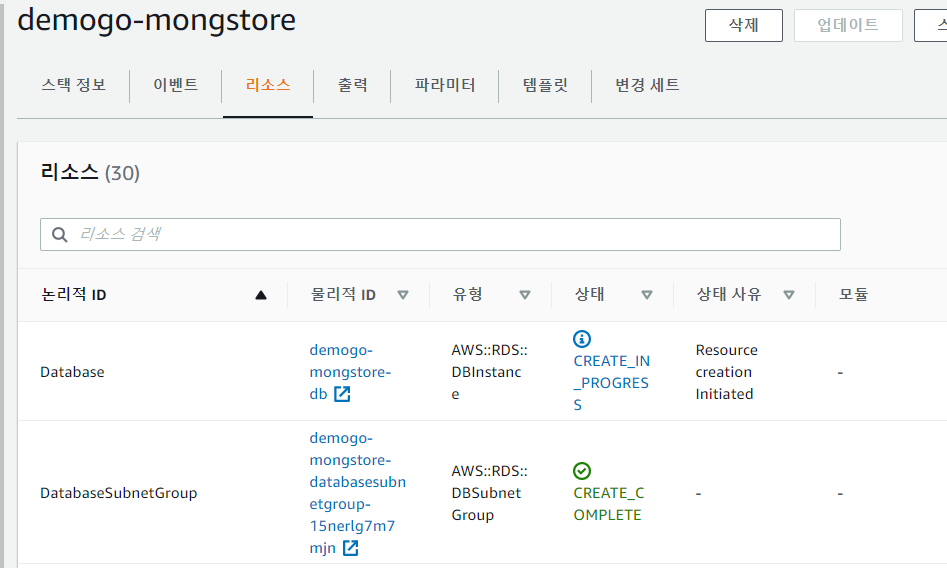
2. [데이터베이스 데이터 수집하기]

데이터베이스에 저장된 구매 테이블, 제품 테이블을 S3로 보낸다.
이 과정에서 고객이 분석을 위해 데이터를 준비하고 로드할 수 있게 ETL 서비스를 제공하는 Glue를 사용한다.
AWS Glue - 관리형 ETL 서비스 - Amazon Web Services
AWS Glue는 새 데이터가 도착하면 ETL 작업을 실행할 수 있습니다. 예를 들어 AWS Lambda 함수를 통해 ETL 작업을 트리거하여 Amazon S3에 새로운 데이터가 저장되는 대로 ETL 작업이 실행되도록 할 수 있습
aws.amazon.com
[S3 bucket 생성 및 구성하기]
- 분석 환경을 위한 데이터 저장소
- 데이터를 모아주는 Datalake 역할
- S3에서 bucket 생성 : 이름은 demogo-mongstore-fullmoon
- US East (N.Virginia)로 Region 선택
bucket이 생성되면 권한 설정을 등록해야 합니다.
추천 캠페인 생성 시 Personalize 서비스가 S3 버킷에 접속할 수 있도록 bucket 정책을 추가해줘야 하거든요.
S3 > bucket 선택 > 권한 > 버킷 정책 > [편집]
[권한 정책]
{
"Version": "2012-10-17",
"Id": "PersonalizeS3BucketAccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::demogo-mongstore-fullmoon",
"arn:aws:s3:::demogo-mongstore-fullmoon/*"
]
}
]
}* fullmoon > 바꾸셔야 합니다.
bucket이 생성되면 해당 bucket을 AWS 서비스들이 private 하게 접속할 수 있도록
S3에 대한 VPC endpoint를 생성하고 VPC와 연결해야 합니다.
VPC > Endpoint > Endpoint 생성
- Service category : AWS services
- Service Name : com.amazonaws.us-east-1.s3
- Type : Gateway

- VPC : vpc-xxxxx(demogo-mongstore)
- Configure route tables : 모든 route table 선택
- Policy : Full Access

[데이터베이스 데이터 CRAWLING 하기]
데이터베이스의 데이터 구조를 AWS Glue 서비스는 알 수 없기 때문에 ETL을 하려면 먼저 크롤링 작업을 해야 합니다.
- Glue Crawler
1) 저장된 데이터를 스캔
2) 스키마와 파티션 구조 등을 자동으로 추론
3) 데이터 카탈로그 생성
Glue > 데이터 카탈로그 > 데이터베이스 > 데이터베이스 추가
Name : demogo-mongstore-database
데이터 카탈로그 > 연결 > 연결 추가 > 정보 입력

- Connection name : demogo-mongstore-rdsconnection
- Connection type : Amazon RDS
- Database engine : MySQL
- Instance : demogo-mongstore-db
- Databasename : mongstore
- Username : admin
- Password : Welcome12#
연결 테스트를 합니다.

Waiting...

그럼 이제 크롤링 작업을 합니다.
크롤러 > 크롤러 추가 > 정보 입력
* 크롤러의 주기를 일회성으로 지정하지만, 원할 경우 주기적으로 크롤링을 수행하여 데이터베이스의 메타데이터를 관리할 수 있습니다.
- Crawler name : demogo-mongstore-rdscrawler
- Crawler source type : Data stores
- Repeat crawls of S3 data stores : Crawl all folders
- Choose a data store : JDBC
- Connection : demogo-mongstore-rdsconnection
- Include path : mongstore/%
- Add another data store : No
- IAM role : demogo-mongstore-GlueIamRole-xxxxx
- Frequency : Run on demand (온디맨드 실행)
- Database : demogo-mongstore-database
- Prefix added to tables : rds_ (이 크롤러가 생성한 모든 테이블을 식별합니다.)
생성 후 방금 생성한 크롤러를 선택하고 [크롤러 실행]을 진행합니다.


크롤링이 완료되면 왼쪽 메뉴의 Tables로 이동합니다.
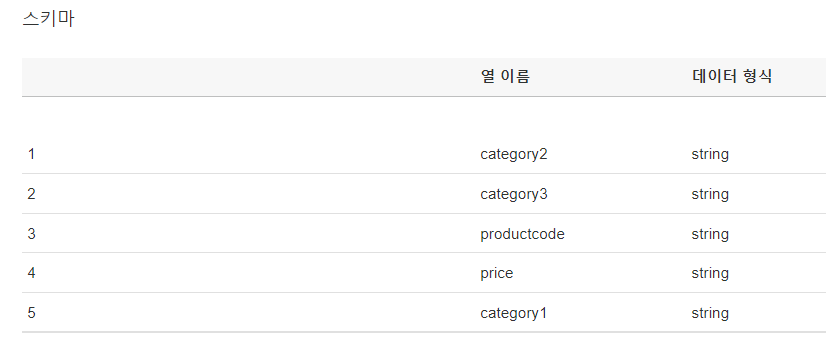
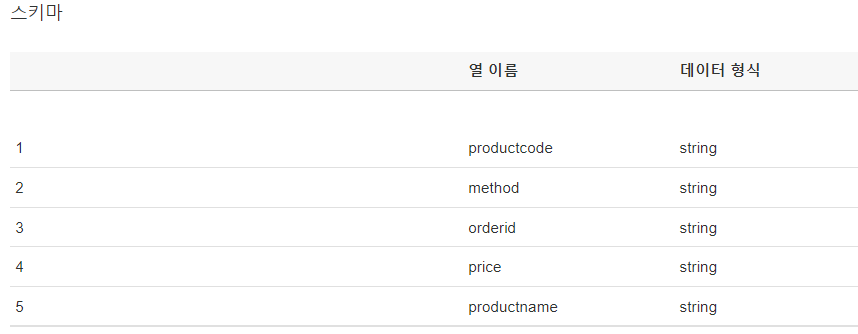
RDS의 제품 데이터, 구매 데이터 정보를 담고 있는 product, purchase 테이블로
rds_mongstore_product, rds_mongstore_purchase 테이블로 생성된 것을 확인할 수 있습니다.

각각 클릭하면 해당 테이블의 칼럼 정보 등의 메타데이터를 Glue에서 확인이 가능합니다.
[데이터베이스 데이터 ETL 전송하기]
Glue의 ETL job을 통해 데이터베이스에 저장되어 있는 purchase 테이블, product 테이블 데이터들 S3로 보내서 쌓습니다.
Glue의 기능으로 수행합니다.
* RDS의 데이터는 Glue Job을 사용하지 않고도 RDS 스냅샷 데이터를 S3로 보낼 수 있습니다.
ETL > 작업 > 작업 추가
- Name : demogo-mongstore-rds(product)-etl
- IAM : demogo-mongstore-GlueIamRole-XXXX
나머지는 두고 [다음]
* 만약 [고급 속성] > 작업 북마크를 활성화 한다면 Glue의 상태 정보를 유지하여 ETL job을 실행 할 때 이미 처리가 된 데이터를 저장하게 됩니다. 그래서 만약에 새로운 데이터가 추가 된다면 추가된 데이터'만' ETL 작업을 수행이 가능합니다.
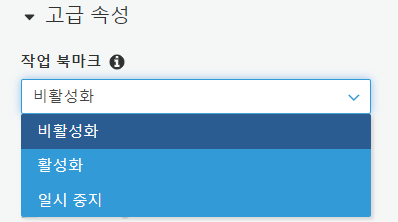
[관계형 데이터베이스(JDBC 연결) 입력 소스]
제한된 사용 사례의 한정으로 북마크 사용 : 기존 row에 수정사항이 일어나지 않으며 새로운 row만 insert되는 데이터 형태의 사용 경우
작업 북마크 : 입력 소스에서도 테이블의 기본 키가 순차적일 경우

변환할 대상 : ‘rds_mongstore_product’ 테이블 선택
Transform type : 스키마 변경 > [다음]
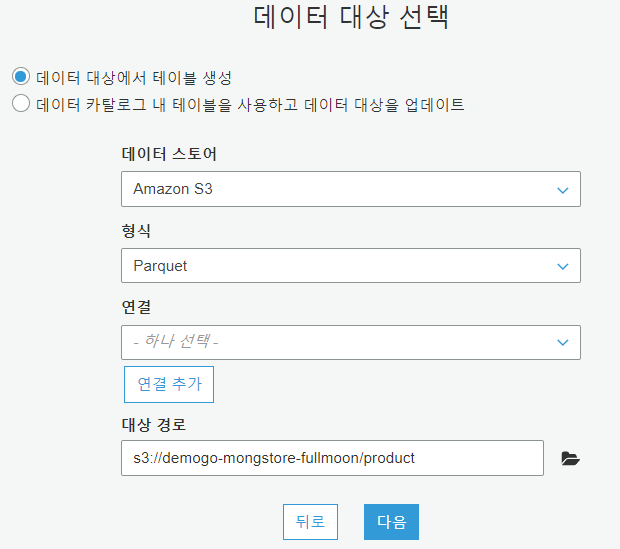
Data target : Create tables in your data target 선택
- Data store : Amazon S3
- Format : Parquet
- Target path : s3://demogo-mongstore-fullmoon/product
- Schema : [Save job and edit script] 클릭
[ 작업 실행 ] 을 클릭 후 Glue 페이지에서 ETL>Jobs 에서’demogo-mongstore-rds(product)-etl’의 job이 running 중인 것을 확인할 수 있습니다.

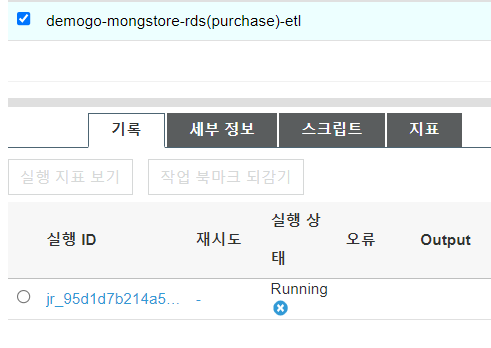
동일하게 Purchase 테이블에 대한 ETL도 수행합니다.
- Name : demogo-mongstore-rds(purchase)-etl
- IAM : demogo-mongstore-GlueIamRole-XXXX
- Data store : Amazon S3
- Format : Parquet
- Target path : s3://demogo-mongstore-fullmoon/purchase

[작업 실행 ] 을 클릭 후 Glue 페이지에서 ETL>Jobs 에서’demogo-mongstore-rds(purchase)-etl’의 job이 running 중인 것을 확인할 수 있습니다.
S3에서 한번 확인해보겠습니다.

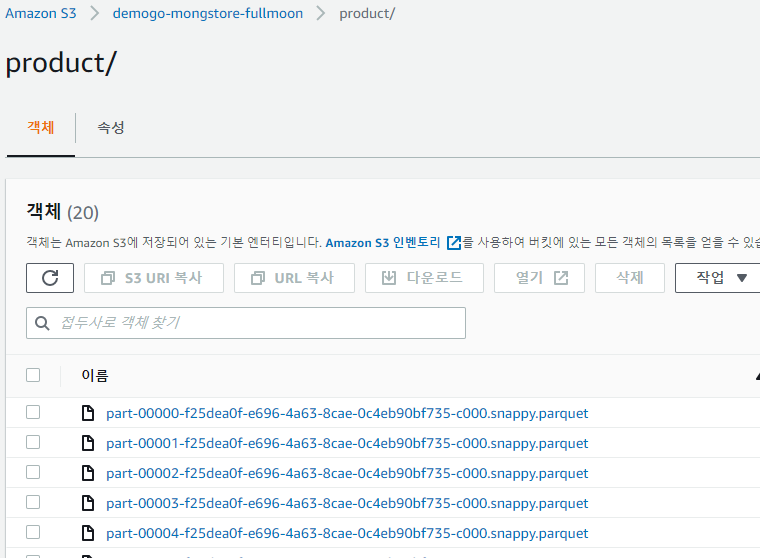
여기까지 진행 후
[AWS workshop] Ecommerce 유저들을 위한 추천 서비스 구현하기 :: DATA LAKE (2) 웹 엑세스 로그 데이터 수집, 데이터 탐색 및 가공하기
를 진행해보겠습니다.
'STUDY' 카테고리의 다른 글
| [모두를위한클라우드컴퓨팅] Chapter1 - 연습문제 (0) | 2022.10.11 |
|---|---|
| [AWS study] Jenkins를 사용한 AWS CICD (극한의 오류수정인데 무한삽질과 허망한 이유) (0) | 2021.08.31 |
| [AWS workshop] Cloudendure로 Windowserver migration 하기 (0) | 2021.08.29 |
| [AWS workshop] 웹 사이트를 구축하기 (1) 단일 인스턴스 웹 호스팅 (0) | 2021.08.26 |
| [AWS workshop] Ecommerce 유저들을 위한 추천 서비스 구현하기 :: DATA LAKE (2) 웹 Access log 데이터 수집, 데이터 탐색 및 가공하기 (0) | 2021.08.26 |



