
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- azureterraform
- 테라폼상태
- macterminal(user)
- mac(user)
- data개념
- aws
- awsworkshop
- Azure
- 테라폼조건문
- 깃허브기초
- mac user
- 테라폼함수
- githubbasic
- t101
- terraform
- pptpdf로변환
- cidrhost로EC2의ENI에10개의ip를 장착
- 테라폼조건식
- (user)없애기
- 테라폼스터디
- awsglue
- terraform_data
- 가시다스터디
- terraformazure
- pptpdf
- pptxpdf
- (user)terminal
- pythonpptpdf
- azureresource
- t103
- Today
- Total
fullmoon's bright IT blog
[AWS workshop] Ecommerce 유저들을 위한 추천 서비스 구현하기 :: DATA LAKE (2) 웹 Access log 데이터 수집, 데이터 탐색 및 가공하기 본문
[AWS workshop] Ecommerce 유저들을 위한 추천 서비스 구현하기 :: DATA LAKE (2) 웹 Access log 데이터 수집, 데이터 탐색 및 가공하기
휘영청 2021. 8. 26. 01:10※ 본 글은 Study 용으로 AWS workshop 실습 내용을 정리한 것입니다.
실습 개요 :: DataLake on AWS
실습 개요 Ecommerce 유저들을 위한 추천 서비스 구현하기 이번 워크샵에서는 가상의 시나리오를 통해 추천 서비스를 구현해봅니다. 추천 서비스를 구현하기 위해서는 발생하는 데이터를 수집하
public-aws-workshop.s3-website.us-east-1.amazonaws.com
[목차]
1. 사전 준비
2. 데이터베이스 데이터 수집하기
3. 웹 Access log 데이터 수집하기
4. 데이터 탐색 및 가공하기
5. 추천 캠페인 생성하기 (Optional)
6. 자원 삭제하기
[AWS workshop] Ecommerce 유저들을 위한 추천 서비스 구현하기 :: DATA LAKE (1) 사전 준비, 데이터베이스
※ 본 글은 Study 용으로 AWS workshop 실습 내용을 정리한 것입니다. 실습 개요 :: DataLake on AWS 실습 개요 Ecommerce 유저들을 위한 추천 서비스 구현하기 이번 워크샵에서는 가상의 시나리오를 통해 추
fullmoon-hwi.tistory.com
[AWS workshop] Ecommerce 유저들을 위한 추천 서비스 구현하기 :: DATA LAKE (1) 사전 준비, 데이터베이스 데이터 수집하기
이전의 글!
3. [웹 Access log 데이터 수집하기]

이전에 구매데이터를 S3로 보내서 쌓았다면
이번에는 웹사이트를 방문하는 User들의 Access log를 S3로 보내서 쌓아봅니다.
User들이 방문하는 log들은 당연히 웹 페이지의 정보를 담고 있어서
User들의 관심 제품을 유추 및 추천 아이템 생성으로 정말 좋지 않을까요!!!
Amazon Kinesis Data Firehose로 쌓아볼 예정입니다. (고객들이 실시간으로 접속해서 데이터를 수집해야하니까)
Amazon Kinesis Data Firehose
- 스트리밍 데이터 레이크 , 데이터 스토어 및 분석 도구에 가장 쉽고 안정적으로 로드하게 도와주는 서비스
[KINESIS DATA FIREHOSE DELIVERY STREAM 생성하기]
데이터를 보낼 대상이 되는 전송 스트림을 미리 생성합니다.
Kinesis > Kinesis Data Firehose > Create delivery stream
Setting을 합니다. Workshop이랑 달라서 정리합니다!
먼저 data stream을 생성합니다.
이름은 demogo-mongstore-deliverystream으로 합니다 나중에
여기서 필요하더라구요 !
[ Choose source and destination ]
Source : Direct PUT
Destination : Amazon S3
[ Delivery stream name ]
Delivery stream name : demogo-mongstore-deliverystream
[ Transform and convert records ]
Data transformation, Record format conversion : Disable
S3 bucket : S3://demogo-mongstore-fullmoon
Destination은 S3를 선택합니다.
아래 S3 bucket에서는 이전에 만든 demogo-mongstore-fullmoon을 선택하고 S3 prefix에 accesslog를 입력합니다.
이 설정으로 해당 delivery stream으로 보내진 데이터는
demogo-mongstore-fullmoon bucket의 accesslog 폴더로 보내지게 됩니다.
S3로 데이터를 전송할 주기와 압축 여부를 선택할 수 있습니다.
- Buffer size : 1MB
- Buffer interval : 60 seconds (버퍼사이즈와 버퍼주기 조건 중 더 빨리 만족하는 조건에 맞추어 데이터를 전송합니다.)
- S3 compression : GZIP (데이터를 압축해서 전송함으로써 네트워크, 스토리지를 모두 효율적으로 사용할 수 있습니다.)
- S3 encryption : Disable
- Error logging : Enable
- Permissions 항목에 위치한 IAM role에서는 [Create orr Update IAM role KinesisFirehoseRole-demogo…..] 버튼을 클릭합니다. 필요한 정책이 포함된 IAM 역할을 자동으로 생성합니다.
[생성] 클릭!
[웹 서버 Access log KINESIS로 전송하기]
웹 서버에 접속해서 발생하고 있는 실시간 Access log를 방금 생성한 Kinesis firehose delivery stream으로 전송합니다.
Python용 AWS SDK인 Boto3를 사용해서 전송하는 방법으로 해보겠습니다.
EC2 > instance : ‘demogo-mongstore-webserver’
각자의 방법으로 접속하세요 !
저는 MobaXterm 으로 접속.
python3 firehose.py데이터가 발생하는 것을 확인합니다.
Access log 데이터가 모두 전송되는데 약 3분 정도의 시간이 필요하더라구요. 기다려주세요.
그 후 S3에 생성된 Access log가 S3에 저장된 것을 확인할 수 있어요.
4. [데이터 탐색 및 가공하기]
데이터베이스 & 웹 서버의 데이터를 S3로 모두 모았으나
S3에 저장된 원본데이터는 환경에 따라 스키마나 형식이 모두 다를 수 있습니다.
그걸 사용자에 맞게 AWS Personalize 서비스에서는 세 가지 유형의 기록 데이터 세트를 인식하기 때문에 확인할 수 있습니다.
사용자 – 사용자에 대한 메타데이터를 제공합니다. (필수 필드 : USER_ID(string))
항목 – 항목에 대한 메타데이터를 제공합니다. (필수 필드 : ITEM_ID(string))
상호 작용 – 사용자와 항목 간의 과거 상호 작용 데이터를 제공합니다. (필수 필드 : USER_ID(string), ITEM_ID(string), TIMESTAMP(long))
[ AWS Glue]
완전 관리형 ETL(추출, 변환, 로드) 서비스로, 효율적인 비용으로 간단하게 여러 데이터 스토어 간에 원하는 데이터를 분류, 정리, 보강, 이동
중앙 메타데이터 리포지토리, 자동적으로 Python 및 Scala 코드를 생성하는 ETL 엔진 및 종속적 해결 방안, 작업 모니터링 및 재시도를 관리하는 유연성 스케줄러로 구성
Glue의 crawling 작업을 통해 데이터 카탈로그를 생성하고,
이 데이터를 바탕으로 Glue의 ETL job 기능을 활용하여 Scala 코드로 데이터를 변환합니다.
[S3에 적재된 데이터베이스 데이터와 웹 서버 액세스 로그 CRAWLING하기]
S3에 저장된 원본 데이터는 AWS Athena서비스를 통해 데이터를 가공해야합니다.
먼저 ! S3에 저장된 원본데이터의 스키마를 파악할 수 있도록 Crawling 작업이 선행되어야 합니다.
Glue의 Crawler를 통해 S3에 저장된 데이터를 스캔하고 스키마와 파티션 구조 등을 자동으로 추론합니다.
그 이후 데이터 카탈로그를 생성합니다.
- Crawler name : demogo-mongstore-s3crawler
- Crawler source type : Data stores
- Repeat crawls of S3 data stores : Crawl all folders
product, purchase, Accesslog가 들어있는 S3 버킷 위치를 지정해줍니다.
Add another data store 단계에서 ‘No'를 선택합니다.
IAM Role 단계에서 [Choose an existing IAM role]을 선택
IAM role : demogo-mongstore-GlueIamRole-xxxxx
Schedule 단계에서 해당 크롤링이 수행될 주기를 지정합니다.
Frequency : Run on demand
*본 lab에서는 크롤러의 주기를 일회성으로 지정하지만, 원할 경우 주기적으로 크롤링을 수행하여 데이터베이스의 메타데이터를 관리할 수 있습니다.
Ouput 단계에서 크롤링 후 테이블을 생성해 줄 Glue 데이터베이스 위치를 지정합니다.
Database : demogo-mongstore-database
마지막으로 [Finish] !
크롤러 목록에서 방금 생성한 크롤러를 선택하고 [Run crawler]
크롤링이 완료되면 왼쪽 메뉴의 Tables로 이동하여 S3에 적재되었던 RDS의 product, purchase 데이터와 웹 서버의 액세스 로그 데이터가 테이블로 생성된 것을 확인할 수 있습니다.
[소스 데이터 탐색하기]
크롤링 된 데이터는 Athena 서비스를 통해 SQL문을 사용하여 데이터를 조회할 수 있어요.
무슨 정보가 있는지 확인해봅시다.
그 전에
[사전작업]
Athena 서비스를 처음 사용한다면 쿼리를 실행하기 전 쿼리문의 output을 저장할 S3 버킷을 지정해야합니다.
S3에서 미리 Athena 결과물을 저장할 버킷을 생성합니다.
생성된 테이블 중 ‘accesslog2021’ 테이블 왼쪽 체크박스를 눌러 테이블을 선택합니다.
[작업] > 데이터 보기
Athena 페이지에서 상단 메세지의 파란 글씨 부분을 클릭합니다.
Athena 서비스로 연결되어 테이블의 데이터를 조회하는 쿼리문이 작성된 것을 볼 수 있습니다.
[쿼리 실행] 버튼을 클릭하면 데이터가 조회됩니다.
* 실제 데이터가 GZIP으로 압축되어있어서 별도의 압축해제 작업 없이 데이터를 조회/수정하는 것이 가능합니다.
웹 서버의 accesslog 데이터가
세션ID, 사용자가 방문한 URL, 이벤트, 방문시간, 사용 디바이스, 유저 ID, 상태 정보, 액세스 로그 생성 시간에 따른 파티션 정보
등으로 구성된 것을 확인할 수 있습니다.
같은 방법을 사용하여 Product 테이블과 Purchase 테이블의 데이터 정보를 동일하게 확인해 볼 수 있습니다.
예를 들어 10번 유저의 구매이력이 궁금하다면 아래 쿼리를 통해 확인할 수 있습니다.
SELECT *
FROM "demogo-mongstore-database"."accesslog2021"
WHERE userid='10';
[데이터 가공하기]
S3에 저장된 액세스로그와 product, purchase 테이블들을 확인했습니다.
그 다음 personalize 서비스에서 사용 가능한 데이터 형태로 가공을 합니다.
다시 한번 등장하는 Glue 서비스의 ETL 작업을 사용합니다.
ETL(추출, 변환 및 로드) 스크립트를 자동 생성하거나, 사용자가 원하는 방식으로 작성하여 사용할 수 있습니다.
Glue > ETL > Job > [Add job] > ETL job 생성
1. 항목 데이터 셋으로 사용할 데이터를 가공합니다.
- Name : demogo-mongstore-items-dataset
- IAM : demogo-mongstore-GlueIamRole-XXXX
- Type : Spark(default)
- Glue version : Spark 2.4, Python 3(Glue Version 2.0)
- This job runs : A new script to be authored by you
[연결] 단계에서는 작업 저장 및 스크립트 편집으로 넘어갑니다.
스크립트를 입력할 수 있는 화면이 나타나면 아래의 스크립트를 입력합니다.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
##create dynamic frame
digital_df = glueContext.create_dynamic_frame.from_catalog(database='demogo-mongstore-database', table_name='product').toDF()
digital_df.createGlobalTempView("productview")
##sql query
client_df = spark.sql("SELECT productcode as ITEM_ID, productname as PRODUCTNAME, category1||'|'||category2||'|'||category3 as CATEGORY FROM global_temp.productview")
##write output to S3
client_df.repartition(1).write.format('csv').option('header', 'true').save('s3://demogo-mongstore-fullmoon/personalize-items')
job.commit()* 이 스크립트는 personalize 서비스 트레이닝 시 필요한 포맷으로 데이터를 변환시켜 줍니다.
AS-IS (데이터베이스 product 테이블)
TO-BE(‘personalize-items’ S3 버킷의 csv 파일)
[저장] 을 클릭 후 [작업 실행] 을 누릅니다. 작업 실행이 돌아가면 X 버튼을 누릅니다.
2. 상호작용 데이터 셋으로 사용할 데이터를 가공합니다.
똑같이
Glue > ETL > Job > [Add job] > ETL job 생성
- Name : demogo-mongstore-interactions-dataset
- IAM : demogo-mongstore-GlueIamRole-XXXX
- Type : Spark(default)
- Glue version : Spark 2.4, Python 3(Glue Version 2.0)
- This job runs : A new script to be authored by you
[연결] 단계에서는 작업 저장 및 스크립트 편집으로 넘어갑니다.
스크립트를 입력할 수 있는 화면이 나타나면 아래의 스크립트를 입력합니다.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
import datetime
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
##create dynamic frame
digital_df = glueContext.create_dynamic_frame.from_catalog(database='demogo-mongstore-database', table_name='purchase').toDF()
digital_df.createGlobalTempView("purchaseview")
digital_df = glueContext.create_dynamic_frame.from_catalog(database='demogo-mongstore-database', table_name='accesslog2021').toDF()
digital_df.createGlobalTempView("accesslog2021view")
##sql query
client_df = spark.sql("SELECT userid as USER_ID, REGEXP_REPLACE(pageurl, '[^0-9]+','') as ITEM_ID, to_unix_timestamp(CAST(time AS timestamp)) as TIMESTAMP, 'view' as EVENT_TYPE FROM global_temp.accesslog2021view UNION ALL SELECT userid as USER_ID, productcode as ITEM_ID, to_unix_timestamp(ordertime) as TIMESTAMP, 'order' as EVENT_TYPE FROM global_temp.purchaseview")
##write output to S3
client_df.repartition(1).write.format('csv').option('header', 'true').option('header', 'true').save('s3://demogo-mongstore-fullmoon/personalize-interactions')
job.commit()
* 해당 스크립트는 아래와 같이 personalize 서비스 트레이닝 시 필요한 포맷으로 데이터를 변환시켜 줍니다.
AS-IS (데이터베이스 purchase 테이블, 웹서버의 accesslog)
TO-BE(‘personalize-interactions’ S3 버킷의 csv 파일)
[저장] 을 클릭 후 [작업 실행] 을 누릅니다. 작업 실행이 돌아가면 X 버튼을 누릅니다.
Jobs 목록에서 생성한 ‘demogo-mongstore-items-dataset’과 ‘demogo-mongstore-interactions-dataset’를 클릭하면 각 job들의 상태를 확인할 수 있습니다. 상태가 running 상태에서 succeed 상태로 바뀔 때까지 약 10분에서 20분 정도 기다립니다.
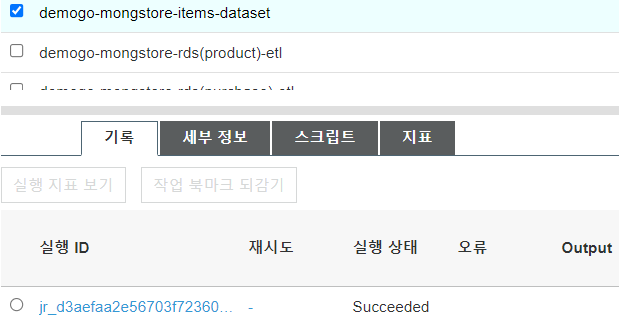
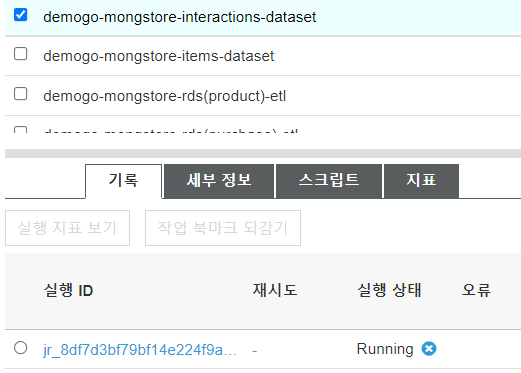
S3에서 확인합니다. > ‘demogo-mongstore-fullmoon’ bucket 에서 ‘personazlie-items’와 ‘personalize-interactions’가 생성된 것을 확인합니다.
5. [캠페인 생성하기] 는 생략합니다 :D
6. 자원삭제하기
✔ PERSONALIZE 서비스 자원 삭제하기
✔ GLUE 서비스 자원 삭제하기
AWS Management console > Glue > Databases 아래 Tables
‘accesslog2021’, ‘product’, ‘purchase’, ‘rds_mongstore_product’, ‘rds_mongstore_purchase’ 테이블 삭제
Databases 아래 Connections
‘demogo-mongstore-rdsconnection’ ‘demogo-mongstore-rdscrawler’와 ‘demogo-mongstore-s3crawler’ 삭제
ETL 아래 Jobs
‘demogo-mongstore~’로 시작하는 4개의 job 삭제
Databases
‘demogo-mongstore-database’ 삭제
✔ KINESIS 서비스 자원 삭제하기
Kinesis > Data Firehose
‘demogo-mongstore-deliverystream’ 삭제
✔ S3 서비스 자원 삭제하기
S3 > ‘demogo-mongstore-fullmoon’ > 삭제
✔ VPC endpoints 삭제하기
VPC > Endpoints > 삭제
✔ CLOUDFORMATION 스택 삭제하기
CloudFormation > ‘demogo-mongstore’스택 > 삭제

휴 힘들었다!
'STUDY' 카테고리의 다른 글
| [모두를위한클라우드컴퓨팅] Chapter1 - 연습문제 (0) | 2022.10.11 |
|---|---|
| [AWS study] Jenkins를 사용한 AWS CICD (극한의 오류수정인데 무한삽질과 허망한 이유) (0) | 2021.08.31 |
| [AWS workshop] Cloudendure로 Windowserver migration 하기 (0) | 2021.08.29 |
| [AWS workshop] 웹 사이트를 구축하기 (1) 단일 인스턴스 웹 호스팅 (0) | 2021.08.26 |
| [AWS workshop] Ecommerce 유저들을 위한 추천 서비스 구현하기 :: DATA LAKE (1) 사전 준비, 데이터베이스 데이터 수집하기 (0) | 2021.08.25 |



